Introduction: The End of the Transformer Era?
Since 2017, the Transformer architecture has been the undisputed engine of the AI revolution, powering everything from ChatGPT to advanced image generators. However, this king now faces a formidable challenger. In 2025, the Mamba architecture, built on Structured State Space Models (SSMs), has emerged from research labs into practical applications, offering a solution to the Transformer's most significant weakness: its computational nightmare with long sequences. While Transformers struggle with quadratic computational scaling, Mamba achieves linear scaling, enabling it to process contexts of up to one million tokens—a capability that is already unlocking new possibilities in genomics, long-form content analysis, and advanced conversational AI.
What is Mamba? A Simple Breakdown
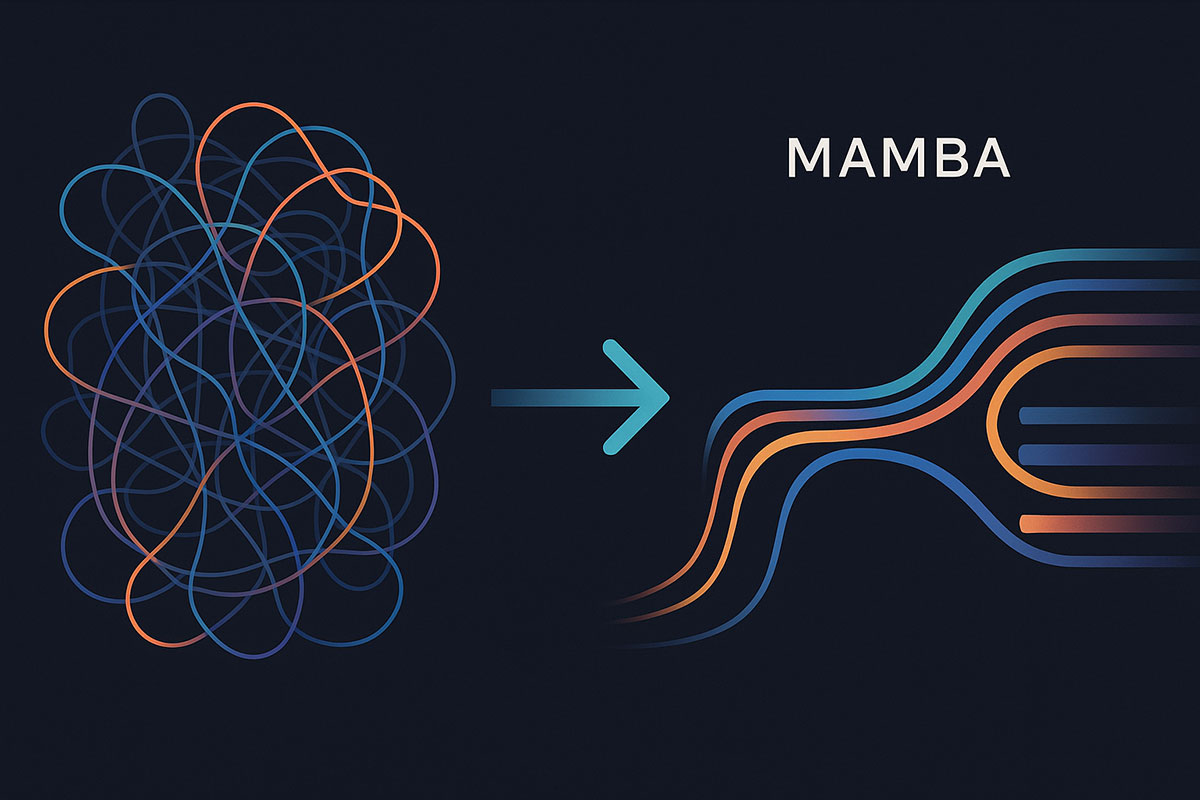
At its core, Mamba is a novel neural network architecture designed for sequence modeling. It discards the standard Transformer's self-attention mechanism, which is responsible for its high computational cost. Instead, Mamba is inspired by classical state space models from control theory, which maintain a hidden state that evolves over time as new data arrives. Think of it like this: while a Transformer must constantly look back at every single word in a sentence to understand the next one, Mamba compresses the important information into a hidden state, which it efficiently updates with each new word. This fundamental difference is the source of its remarkable efficiency.
The Secret Sauce: Selectivity
The key innovation that makes Mamba so powerful is what its creators call selectivity. Previous state space models used fixed parameters to govern how the hidden state updates. Mamba, however, makes these parameters input-dependent. This means the model can dynamically decide which information to retain in its state and which to discard. For example, when processing a sentence, it can learn to hold onto crucial nouns and verbs while filtering out less important filler words. This selective mechanism gives Mamba a nuanced "memory" that is far more sophisticated than earlier recurrent models.
Mamba vs. Transformer: A Head-to-Head Comparison
To understand why Mamba is causing so much excitement, it's essential to see how it stacks up against the established Transformer architecture. The differences are not just incremental; they are foundational.
| Feature | Transformer | Mamba |
|---|---|---|
| Core Mechanism | Self-Attention | Selective State Space Model |
| Computational Complexity | O(n²) with sequence length | O(n) with sequence length |
| Handling Long Sequences | Memory-intensive and slow | Highly efficient and fast |
| Typical Context Window | Thousands to hundreds of thousands of tokens | Up to 1 million+ tokens |
| Inference Speed | Standard | Up to 5x faster than equivalent Transformers |
| Memory Usage | High (stores full attention matrix) | Low (maintains compressed hidden state) |
As the table shows, Mamba's linear scaling is a game-changer. For tasks like analyzing entire books, hours of audio, or lengthy codebases, Mamba can perform inferences significantly faster and with less memory, making it not just better, but also more cost-effective to run.
Real-World Applications of Mamba in 2025
The theoretical advantages of Mamba are now being proven in practical applications across diverse fields. In 2025, we are seeing deployments that were previously hampered by the limitations of Transformer models.
- Genomics and Bioinformatics: Mamba's ability to process extremely long sequences makes it ideal for analyzing DNA and protein sequences. Researchers are using it to identify patterns and predict structures across entire genomes, accelerating drug discovery and personalized medicine.
- Long-Form Content Processing: AI models can now analyze and summarize entire books, legal documents, or lengthy reports without losing context. This is revolutionizing academic research, legal discovery, and business intelligence.
- Advanced Conversational AI: Mamba-based conversational agents can maintain coherence and context over incredibly long dialogues, remembering details and nuances from conversations that started hundreds of messages ago. This leads to more natural and helpful AI companions.
- Audio and Video Processing: Projects like Video Vision Mamba (ViViM) are applying the architecture to video understanding, allowing models to process long video clips for content analysis, action recognition, and automated editing with high efficiency .
Challenges and the Road Ahead
Despite its promise, Mamba is not without challenges. The architecture is complex to implement, requiring specialized knowledge that is not yet as widespread as expertise in Transformers. Furthermore, the ecosystem of tools, pre-trained models, and research around Transformers is vast, and Mamba has some catching up to do. However, the pace of adoption is rapid. The research community has already produced variants like Vision Mamba for computer vision and U-Mamba for medical imaging, showing the architecture's versatility .
The future likely lies not in a single architecture dominating all others, but in hybrid models. Researchers are already exploring ways to combine the strengths of Mamba's efficient long-range modeling with the power of Transformer-style attention for local patterns, creating even more capable and efficient AI systems.
Related Reading
- Beyond Transformers: The Future of LLM Architectures
- AI in Healthcare 2025: Market Trends and Breakthroughs
About the Author
Girish Soni is the founder of TrendFlash and an independent AI strategist covering artificial intelligence policy, industry shifts, and real-world adoption trends. He writes in-depth analysis on how AI is transforming work, education, and digital society. His focus is on helping readers move beyond hype and understand the practical, long-term implications of AI technologies.