The Crisis of Trust in AI-Driven Science
In 2025, a landmark paper announced the discovery of a novel antibiotic candidate, identified not by a decade-long lab campaign, but by an AI model screening millions of molecular structures. The celebration was tempered by a profound, unanswered question from the research team: "How did the AI know?"
This moment captures a critical turning point. Artificial intelligence is no longer just a tool for crunching numbers; it is an active participant in the scientific method, generating hypotheses, designing experiments, and uncovering patterns invisible to the human eye. From predicting protein folds with AlphaFold to simulating climate systems and discovering new materials, AI's contributions are undeniable. Yet, as these systems grow more powerful—evolving into the agentic AI systems that can plan and execute complex tasks—their inner workings become more inscrutable. We are building geniuses that cannot explain their own thoughts.
For science, this is an untenable paradox. The core of the scientific method is not just finding answers, but understanding the 'why' behind them—the causal relationships, the underlying mechanisms, the reproducible logic. A black-box prediction, no matter how accurate, is a dead end for knowledge. It offers a result but robs us of insight. As researchers at institutions like Stanford have emphasized, there is now a "mandate to open AI's black box" in scientific contexts. This drive for AI interpretability is transforming AI from an opaque oracle into a collaborative, reasoning partner we can truly trust.
Why "Black Box" AI is Scientifically Unacceptable
The scientific process is built on a foundation of falsifiability, reproducibility, and mechanistic understanding. A traditional experiment provides a narrative: you formulate a hypothesis based on existing theory, design an intervention, observe the outcome, and iteratively refine your understanding of the causal chain.
Current state-of-the-art AI, particularly large deep learning models and foundation models, shatters this narrative. When a neural network with hundreds of billions of parameters identifies a promising drug candidate, it does so through a labyrinth of multidimensional calculations that are effectively impossible for a human to trace. This creates several fundamental problems:
- The Reproducibility Crisis: If we don't know why the AI made a prediction, we cannot reliably reproduce the logical steps. The same model might fail spectacularly on a seemingly similar input, a phenomenon known as "adversarial fragility."
- The Insight Gap: A successful prediction does not equal new knowledge. Discovering that a molecule works is valuable, but discovering why it works unlocks principles that can guide the design of an entire new class of therapeutics.
- Hidden Bias and Artifacts: AI models can and do learn shortcuts. A model might appear to diagnose a disease from medical imagery but is actually keying on a hospital's scanner signature in the corner of the image. Without interpretability, these dangerous artifacts go undetected.
As AI pioneer Yann LeCun has argued, pure large language models (LLMs) that predict the next word are a potential "dead end" for true intelligence because they lack a grounded model of reality. They can describe physics without understanding it. For science, we need AI that doesn't just describe the world but comprehends its underlying rules—a shift toward models with genuine scientific reasoning capability.
New Techniques for Dissecting AI Reasoning
The field of neural network analysis is responding with a toolkit designed to crack open the black box. These techniques can be broadly categorized as post-hoc (analyzing a model after training) and intrinsic (designing models to be interpretable from the start).
Post-Hoc Interpretation: The Autopsy of AI
These methods probe trained models to reverse-engineer their decision-making.
- Feature Visualization and Attribution: Techniques like Saliency Maps and Gradient-weighted Class Activation Mapping (Grad-CAM) highlight which parts of an input (e.g., which pixels in an image or which words in a text) were most influential in the model's output. In bioimaging, this can show whether an AI diagnosing cancer is focusing on the actual tumor tissue or irrelevant background artifacts.
- Probing and Concept Activation Vectors (CAVs): Researchers train simple classifiers to see if specific human-understandable concepts (e.g., "presence of a cell wall" in cellular imagery or "negative sentiment" in scientific text) are encoded in the model's internal layers. This answers questions like, "Did the model learn a biologically relevant concept on its own?"
- Counterfactual Explanations: Instead of asking "Why did you say A?", we ask "What would need to change for you to say B?" For a model rejecting a material as unstable, a counterfactual explanation might show that increasing the bond strength by 5% would flip the prediction. This provides actionable guidance for researchers.
Intrinsic Interpretability: Building Glass Boxes from the Start
This more ambitious approach focuses on designing AI architectures whose reasoning is more transparent by design.
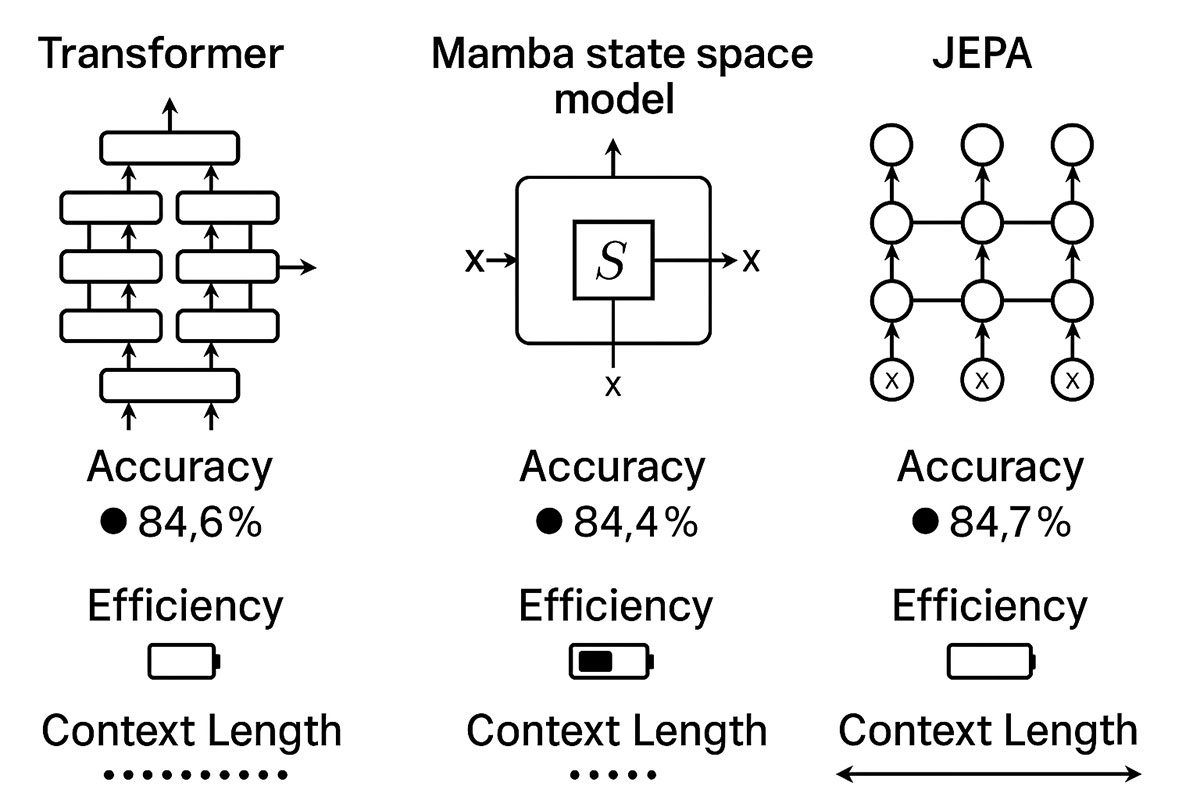
- World Models and Causal Reasoning: A revolutionary shift is moving from models that predict text to world models that predict states in a physical or conceptual environment. Their predictions are based on simulating cause-and-effect, a process that is inherently more traceable than the statistical correlations of an LLM. LeCun's Joint Embedding Predictive Architecture (JEPA) is a prime example, aiming to build AI that learns internal models of the world. This quest for models that understand spatial and physical relationships is explored in our analysis of Large World Models.
- Symbolic AI Integration (Neuro-Symbolic AI): This hybrid approach marries the pattern-recognition power of neural networks with the explicit, logical rules of symbolic AI. The neural network handles messy, real-world data (like a microscope image), and extracts symbolic facts (e.g., "Cell X is undergoing apoptosis"). A logical reasoning engine then applies known scientific rules to these facts to reach a conclusion. Every step in the logical chain is auditable.
- Mechanistic Interpretability: This is the "grand challenge" of the field—aiming to fully reverse-engineer neural networks into human-understandable algorithms. It involves painstaking analysis of individual neurons and circuits within models to map their function. While still in its infancy for giant models, progress here would represent the ultimate triumph of interpretability.
The Toolkit for Transparency: A Comparison
| Technique Category | Primary Goal | Key Method Example | Best For Science When... |
|---|---|---|---|
| Post-Hoc Analysis | Explain a trained model's specific decision. | Feature Attribution (Grad-CAM) | You need to audit or validate the basis of a high-stakes prediction (e.g., drug efficacy). |
| Intrinsic Design | Build models that are transparent by architecture. | World Models / Neuro-Symbolic AI | The research goal is to discover new causal mechanisms or theories, not just predictions. |
| Probing & Testing | Understand what concepts a model has learned. | Concept Activation Vectors (CAVs) | You want to see if an AI has implicitly discovered a meaningful scientific concept in its data. |
Case in Point: Interpretability in Action for Biological Discovery
The theoretical need for Explainable AI (XAI) becomes concrete in life sciences. AI platforms specifically for biomedical research are emerging where transparency isn't a luxury—it's a regulatory and scientific necessity.
Imagine an AI system tasked with exploring the genetic links to a rare disease. A traditional black-box model might output a ranked list of candidate genes. An interpretable, agentic AI system would provide a traceable reasoning trail:
"The agent accessed the latest genomic databases, identified 5 genes with elevated expression in patient samples, cross-referenced them with known protein-protein interaction networks, and hypothesized that Gene X is central because it connects two previously unrelated biochemical pathways. Here is the supporting evidence from 15 relevant studies published in the last 18 months."
This mirrors the autonomous, goal-oriented workflows seen in broader agentic AI applications, where systems break down complex goals, use tools (like research databases), and adapt their approach. In science, the "tools" are lab databases, simulation software, and scientific literature, and the "workflow" is the hypothesis-testing cycle. The platform's ability to deliver "fully traceable insights" and maintain "scientific rigor for regulatory approval" is its core value.
This is the future: AI as a research assistant that not only finds the needle in the haystack but can also explain, in defensible scientific terms, exactly how it found it and why that particular needle matters.
The Road Ahead: Making Transparent AI the Scientific Standard
The journey toward fully interpretable AI in science is a major technical and cultural undertaking. The breakthroughs defining the AI landscape—agentic reasoning, continual learning, and world models—all converge on this goal. As AI transitions from a tool to a colleague, our ability to collaborate with it depends on mutual understanding.
"The true power of agentic AI isn't just in automation; it's in augmentation... When we blend human creativity with AI's analytical capabilities, we create a workforce that's greater than the sum of its parts."
— Insight from Mercer on the human-AI partnership in professional settings.
For scientists and institutions, the path forward involves:
- Demanding Interpretability: Grant agencies and journals should begin to require interpretability assessments for AI-driven discoveries, just as they require statistical reviews.
- Adopting the Right Tools: Prioritize AI platforms and frameworks that offer explainability features, whether for post-hoc analysis or building neuro-symbolic systems.
- Developing AI Literacy: The next generation of scientists must be trained not just in using AI, but in interrogating it—understanding the basics of how models work, their limitations, and how to ask them for explanations.
This shift also demands immense computational resources. The push for transparency and more complex world models is part of the driving force behind Big Tech's unprecedented investments in AI infrastructure and energy sovereignty, seeking the power to fuel the next generation of intelligible AI.
The mandate is clear. To fulfill AI's revolutionary promise in science, we must build systems that don't just give us answers, but that earn our trust by showing their work. The goal is not just a smarter AI, but a deeper, faster, and more profound understanding of the universe itself. The black box must be opened, and the light of scientific inquiry must shine in.
About the Author
Girish Soni is the founder of TrendFlash and an independent AI strategist covering artificial intelligence policy, industry shifts, and real-world adoption trends. He writes in-depth analysis on how AI is transforming work, education, and digital society. His focus is on helping readers move beyond hype and understand the practical, long-term implications of AI technologies.