Introduction: The Quest for Machine Common Sense
For all the dazzling capabilities of large language models, they lack a fundamental human trait: common sense. They can write a sonnet about gravity but don't intrinsically understand that a falling cup will shatter. This critical gap is what pioneering AI scientist Yann LeCun aims to bridge with his latest architectural proposal: the Joint Embedding Predictive Architecture (JEPA). Unlike generative models that predict pixels or words, JEPA learns to create internal "world models"—compressed representations of how the world behaves. This isn't just an incremental update; it's a fundamentally different path toward autonomous, intelligent systems.
Why Current AI Models Hit a Wall
To understand JEPA's breakthrough, we must first see the limitations of today's dominant models. Models like GPT-4 and its successors are primarily autoregressive, predicting the next token in a sequence. This works remarkably well for language but is incredibly inefficient for learning about the physical world.
- They Focus on Surfaces, Not Underlying Causes: They become experts in correlation, not causation. They know "dark clouds" are often associated with "rain" but don't model the atmospheric physics that connects them.
- They are Computationally Wasteful: Reconstructing every detail of an input (like every pixel in a video frame) to learn is overkill. Humans learn that a cup is a cup from a few angles, not by memorizing every possible pixel configuration.
- They Lack a Persistent World Model: Their knowledge is statistical, not grounded in a persistent, internal simulation of reality. This is why they can produce "hallucinations"—statistically plausible but factually incorrect statements.
As LeCun himself argues, pushing the current paradigm further will require exponentially more data and compute, a path that is ultimately unsustainable for achieving human-level intelligence.
How JEPA Works: Predicting in Abstract Space
JEPA introduces a elegant solution to this problem. Instead of predicting precise, low-level details (like the next word or pixel), it learns to predict a representation of the future in a high-level, abstract space.
Imagine watching a video of a person throwing a ball. A generative model might try to predict the exact position of every pixel in the next frame. A JEPA, however, works differently:
- Encoding: It takes the current frame and converts it into a compact, abstract representation—an "embedding"—that captures the essential information (e.g., "person, arm extended, ball in hand").
- Prediction: Inside this abstract space, the model predicts the future representation (e.g., "person, arm follow-through, ball in air").
- Comparison: It then encodes the *actual* future frame and checks if its prediction in the abstract space matches the reality. The model is trained to make these abstract representations as informative as possible while making the prediction task as simple as possible.
This process is called self-supervised learning, and it allows the JEPA to learn a hierarchy of features and concepts without ever being explicitly told what they are. It's learning the rules of the game by watching the gameplay, not by memorizing the rulebook. This approach is far more computationally efficient and leads to more robust representations.
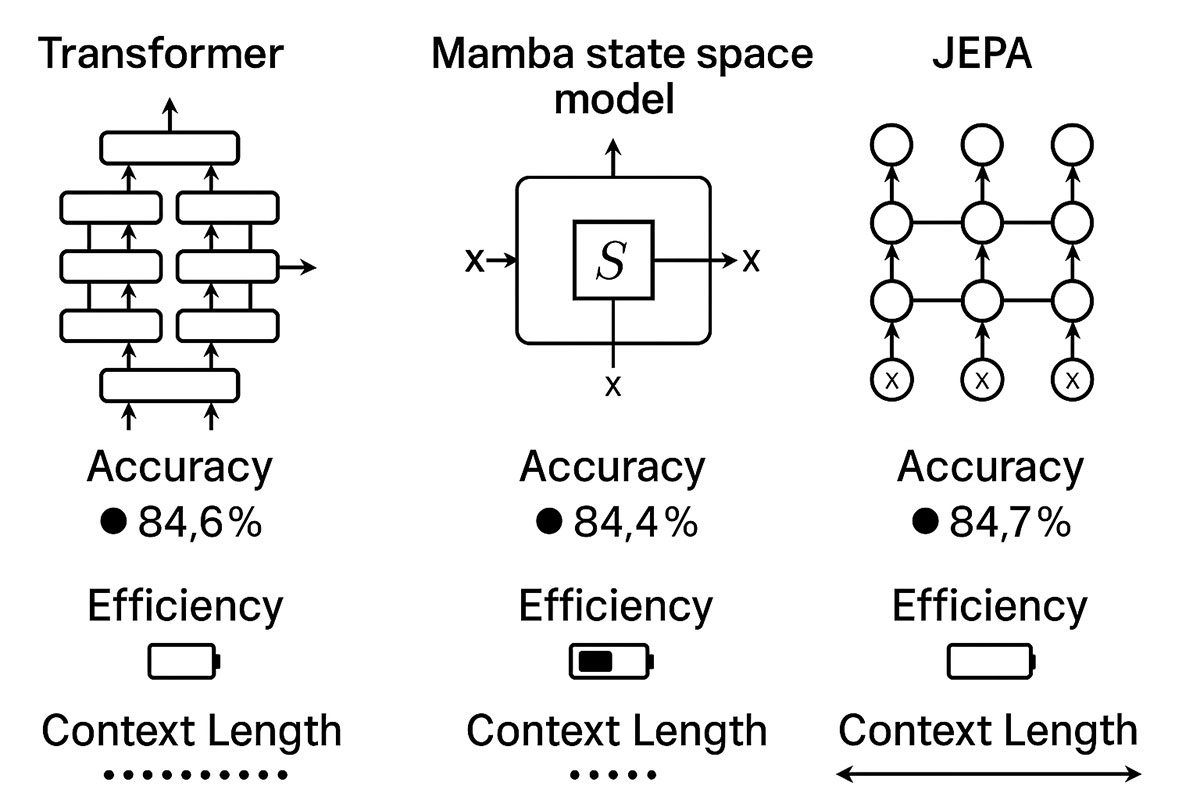
JEPA vs. Transformers: A Fundamental Shift in Philosophy
The following table highlights the core philosophical and technical differences between the dominant Transformer architecture and the emerging JEPA framework.
| Feature | Transformer Architecture | JEPA Architecture |
|---|---|---|
| Primary Goal | Next-token prediction (for LLMs) | Learn a world model |
| Learning Method | Supervised (on labeled data) & Self-supervised (on next token) | Self-supervised (on world states) |
| Output | Precise data (a word, a pixel) | Abstract representation |
| Efficiency | Low for learning world dynamics | High for learning world dynamics |
| Key Strength | Pattern recognition, language manipulation | Reasoning, planning, understanding cause-and-effect |
The Real-World Potential of JEPA-driven Systems
While JEPA is still primarily a research framework, its potential applications are profound. By building systems that understand how the world works, we can overcome some of the biggest hurdles in AI today.
- Truly Autonomous Robotics: A robot with a JEPA-based world model wouldn't just follow pre-programmed commands. It could understand that pushing a block too hard will make it fall off a table, and adjust its force accordingly. It could plan a sequence of actions to achieve a physical goal.
- Advanced AI Assistants: Imagine a virtual coworker that doesn't just retrieve information but can reason about it. You could ask, "If we delay the product launch by two weeks, what is the likely impact on Q3 revenue and customer sentiment?" and it would simulate the outcomes based on its model of business dynamics.
- Scientific Discovery: JEPAs could be trained on scientific data to model complex systems—from molecular interactions to climate patterns—helping researchers generate and test hypotheses at an unprecedented speed.
Challenges and The Road Ahead
JEPA is not a finished product. The architecture, particularly the Hierarchical JEPA (H-JEPA), is an active area of research. Key challenges include designing effective training regimes and scaling the models to the complexity of the real world. However, it represents the most coherent roadmap toward creating AI with human-like understanding. It shifts the focus from "more data" to "smarter learning."
This research dovetails with other emerging architectures, such as Mamba SSM, which also seeks to move beyond the Transformer's limitations in efficient reasoning. As these lines of research converge, we are likely to see a new generation of AI that is less of a statistical parrot and more of a reasoning partner.
Related Reading
- Is LSTM Finally Dead? A Look at the New Mamba SSM Model
- Beyond GPT-4: What JEPA and Mamba Tell Us About the Future of AI Architecture
- The Rise of AI Agents in 2025: From Chat to Action
About the Author
Girish Soni is the founder of TrendFlash and an independent AI strategist covering artificial intelligence policy, industry shifts, and real-world adoption trends. He writes in-depth analysis on how AI is transforming work, education, and digital society. His focus is on helping readers move beyond hype and understand the practical, long-term implications of AI technologies.