The Architecture Wars: Transformers Challenge Deep Learning's Establishment
For a decade, Convolutional Neural Networks (CNNs) dominated computer vision. From AlexNet's breakthrough in 2012 through ResNet and EfficientNet, CNNs provided the architectural foundation for image recognition systems worldwide. Yet between 2020 and 2025, this dominance has been challenged by an unexpected competitor: Transformers, originally developed for natural language processing, now achieving superior performance on vision tasks.
This architectural shift isn't merely academic—it has profound implications for practitioners building vision systems. In 2025, choosing between CNNs and Transformers isn't about which is "better," but about matching the right architecture to specific problem constraints, computational budgets, and organizational contexts.
Understanding this trade-off is essential for anyone working in computer vision and robotics, deep learning, or building autonomous systems powered by vision.
Part 1: The Case for CNNs
Core Principles of Convolutional Networks
CNNs are built on three foundational principles:
- Local Connectivity: Each neuron connects to a small, localized region of the input image (the receptive field)
- Weight Sharing: The same weights (filters) are applied across different regions of the image
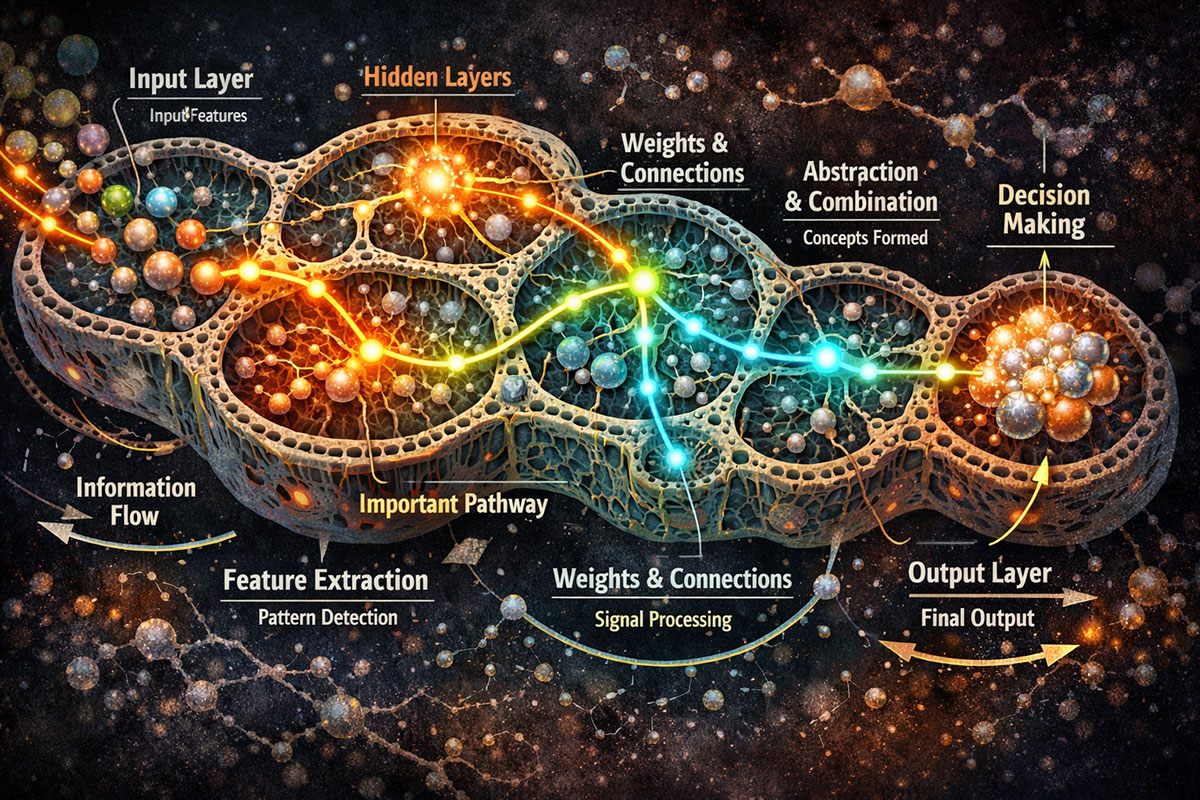
- Hierarchical Feature Learning: Early layers learn low-level features (edges, textures), later layers combine these into high-level concepts (faces, objects)
Computational Efficiency: CNNs' Primary Advantage
CNNs are remarkably efficient. Parameter efficiency through weight sharing, spatial inductive bias for faster learning, and fast inference through optimized implementations make CNNs blazingly fast.
When CNNs Excel
- Deploying on edge devices (phones, embedded systems)
- Real-time inference where latency is critical
- Training with limited data
- Cost-sensitive applications where inference cost matters
- Organizations with existing CNN infrastructure
Part 2: The Transformer Revolution
Vision Transformers (ViT) Architecture
The innovation was surprisingly simple: divide images into patches, treat them as tokens like NLP, and apply standard Transformer architecture.
Transformer Advantages
- Global Context: Every patch can attend to every other patch immediately
- Flexibility: Not biased toward local patterns, learns whatever patterns data exhibits
- Scalability: Performance improves consistently with model size and data volume
- Transfer Learning: Models trained on massive datasets transfer remarkably well
- Multimodal Capability: Transformers naturally handle multimodal inputs
Conclusion: Complementary Rather Than Competitive
The best practitioners understand both architectures deeply and choose based on specific constraints rather than ideological preference. CNNs won't disappear—they're too efficient and proven. Transformers won't monopolize—their computational expense prevents universal adoption.
The future belongs to choosing wisely, combining architectures intelligently, and continuously adapting to new paradigms. Mastering both gives you flexibility and wisdom.
Continue exploring computer vision applications, multimodal AI evolution, and emerging AI architectures.
About the Author
Girish Soni is the founder of TrendFlash and an independent AI strategist covering artificial intelligence policy, industry shifts, and real-world adoption trends. He writes in-depth analysis on how AI is transforming work, education, and digital society. His focus is on helping readers move beyond hype and understand the practical, long-term implications of AI technologies.