Google's HOPE Model: The AI Breakthrough That Changes Everything
In November 2025, Google Research announced something that the AI community has been chasing for years: a machine learning model that can learn continuously without forgetting what it already knows. Called HOPE (Hierarchical Optimizing Processing Ensemble), this self-modifying architecture represents a fundamental breakthrough in how AI systems can evolve and adapt over time. To understand why this matters, you first need to understand the problem it solves.
The Problem: Catastrophic Forgetting Explained Simply
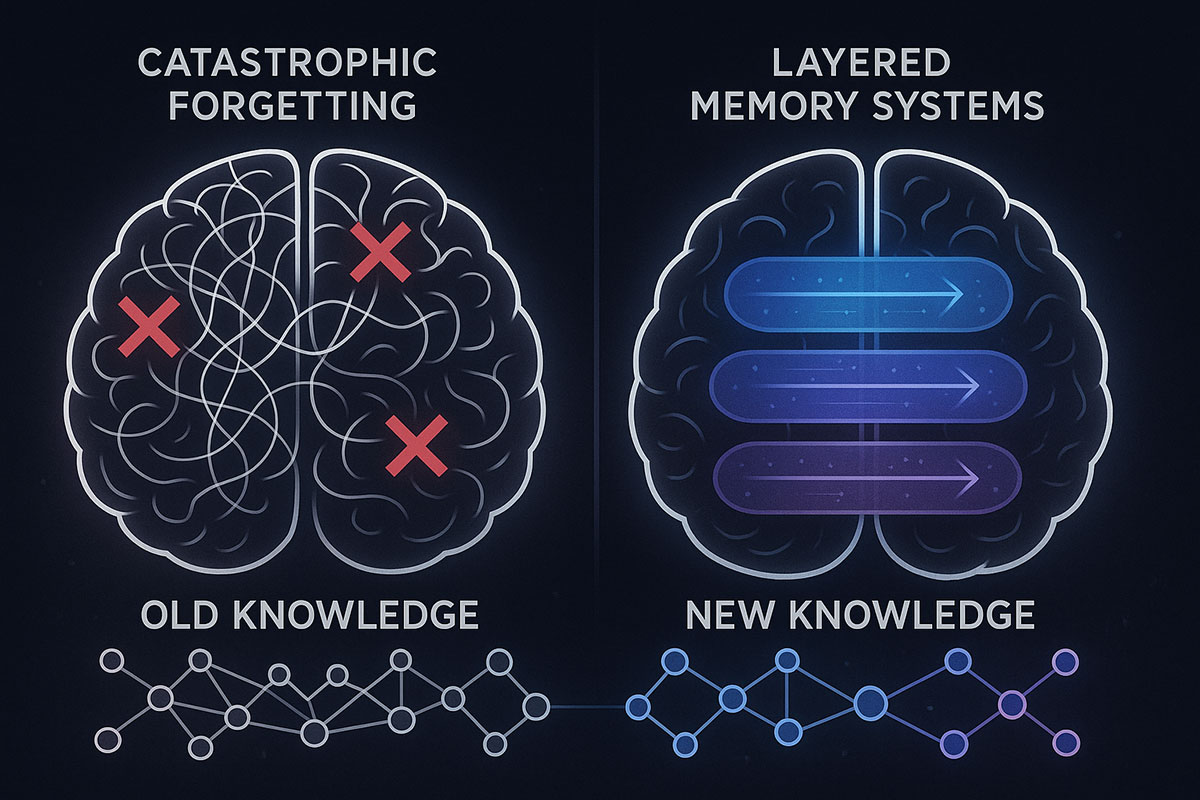
Imagine teaching someone a skill—say, programming in Python. They learn it, practice it, master it. Their brain consolidates the knowledge through repeated interaction. Now imagine that same person learns JavaScript. But when they do, their Python knowledge completely vanishes. They can no longer write a single line of Python code. This is catastrophic forgetting, and it's what happens to nearly every AI model when you try to teach them something new.
Here's why: Traditional AI models learn by adjusting their internal weights (parameters) during training. When you retrain a model with new data, those weight adjustments overwrite previous knowledge. The old patterns are erased, replaced by new ones. This is fine if you're building a static model for a fixed task, but it's catastrophic for AI systems that need to learn and adapt continuously—like robots working in dynamic environments, evolving chatbots that improve through interaction, or medical diagnostic systems that need to incorporate breakthrough research.
Andrej Karpathy, a legendary AI researcher formerly at Google DeepMind, articulated this precisely: "They don't have continual learning. You can't just tell them something and they'll remember it. They're cognitively lacking and it's just not working. It will take about a decade to work through all of those issues." That assessment was made just months before Google announced HOPE—suggesting the company may have found the decade's breakthrough years ahead of schedule.
Why Catastrophic Forgetting Blocks the Road to AGI
Catastrophic forgetting isn't just a technical nuisance. It's arguably the single largest barrier standing between current AI and artificial general intelligence (AGI)—AI systems with human-like learning and reasoning capabilities.
Here's the critical insight: humans learn continuously. A five-year-old learns language, physics intuition, social norms, and thousands of specific facts. A teenager learns calculus, history, biology, and driving—without losing the earlier knowledge. An adult learns new skills, adapts to new environments, and integrates new information into existing worldviews. This lifelong, continual learning is fundamental to human intelligence.
Current AI models can't do this. They can't learn continuously. Each time they encounter new information, the learning process either overwrites old knowledge or requires complete retraining—both options are cognitively and computationally expensive. This limitation has profound implications: it means current AI systems are fundamentally unlike human intelligence in a critical way. They're smart within a narrow domain but brittle when they encounter genuine novelty.
HOPE changes this equation. By enabling genuine continual learning, Google has cracked open a door that was supposed to stay locked until the 2030s.
Nested Learning: The Paradigm Behind the Breakthrough
HOPE is built on a novel theoretical framework called Nested Learning, published as a research paper at NeurIPS 2025 (the premier machine learning conference). Rather than thinking of a model as a single, monolithic learner, Nested Learning treats it as a system of interconnected, multi-level optimization problems that learn simultaneously at different rates.
This is a profound conceptual shift. In traditional deep learning, all parameters update uniformly. In Nested Learning, parameters update at multiple speeds—some fast, some slow, some extraordinarily slow. This mirrors how human brains actually work.
Continuum Memory Systems: The Technical Engine
At the heart of HOPE lies a component called the Continuum Memory System (CMS). In a standard Transformer model, you have two types of memory: short-term memory (the attention mechanism, holding immediate context) and long-term memory (the feedforward network, storing pre-trained knowledge). CMS extends this into a spectrum.
Imagine a chain of memory modules, each with its own update frequency:
- Fast memory (millisecond timescale): Reacts immediately to new information, holds fleeting details and immediate context. Updates continuously.
- Medium memory (second/minute timescale): Consolidates patterns emerging from multiple fast updates. Updates less frequently but captures important trends.
- Slow memory (session/lifetime timescale): Stores fundamental skills and stable knowledge. Updates rarely but durably, preserving core competencies.
This is brilliant because it mimics how human memory actually works. When you meet someone, you have immediate working memory of their face and name (fast). Over minutes, you form impressions about their personality (medium). Over months and years, you integrate them into your stable social knowledge (slow). New information doesn't erase old memories because they operate on different timescales.
Self-Modifying Architecture: Learning How to Learn
But HOPE goes further. It's not just a system with different memory speeds—it's a self-modifying architecture. This means HOPE includes a learned mechanism that can change how it learns.
Concretely, HOPE contains a compact internal module that receives local performance signals (whether a prediction was right or wrong). Based on these signals, this module proposes changes to how the model's internal state should be updated. The model, in effect, learns how to optimize its own learning process. It's learning to learn.
This self-referential mechanism is recursive and theoretically boundless. While standard Titans (the architecture HOPE is based on) only support two levels of parameter updates, HOPE scales to unbounded levels of in-context learning. This is the difference between a model that can adapt and a model that can adapt to how it adapts to new situations.
How HOPE Solves Catastrophic Forgetting
With these components in place, HOPE overcomes catastrophic forgetting through a simple but elegant principle: new knowledge doesn't overwrite old knowledge because they live on different timescales.
When you teach HOPE something new:
- Fast memory modules immediately capture the new information.
- As the model processes more examples, medium memory modules consolidate what's important and what's noise.
- Only information that proves consistently valuable gets promoted to slow memory modules, where it integrates with stable knowledge.
- Importantly: slow memory modules resist updating. They don't erase; they integrate.
The result is that old knowledge remains intact while new knowledge is absorbed. The model learns, adapts, and grows without losing its foundational capabilities. This is genuine continual learning.
Real-World Applications: Where HOPE Transforms AI
Continual learning isn't a theoretical nicety. It enables concrete applications that were previously impossible or prohibitively expensive:
Robotics and Autonomous Systems
A robot trained to perform assembly line tasks can now learn to handle new equipment, new materials, and new processes without retraining from scratch. Each new task is incorporated into its knowledge base. A home robot can learn the layout of a new house, the preferences of new inhabitants, and novel tasks—all while retaining its core motor and navigation skills.
Medical AI Systems
A diagnostic AI trained on current medical knowledge can continuously absorb breakthrough research, emerging treatment protocols, and new disease patterns without losing its foundational diagnostic capabilities. As new research emerges, the system adapts in real-time rather than requiring complete retraining cycles.
Conversational AI and Personal Assistants
An AI assistant can learn a user's preferences, habits, and communication style through continuous interaction. It gets better at serving that specific user over time, remembering past conversations and preferences while maintaining its general knowledge. This is the first real path toward personalized AI that genuinely evolves with you.
Evolving Trading and Financial Systems
Financial AI systems can adapt to market regime changes—bull markets, bear markets, volatility shifts—without losing their foundational understanding of financial principles. They learn new patterns as markets evolve while maintaining stable core strategies.
Autonomous Agents in Complex Environments
AI agents deployed in real-world environments face constant novelty. HOPE enables these agents to learn from each new scenario, integrate discoveries into their decision-making, and improve performance over months and years of deployment—something that was computationally and intellectually infeasible before.
The Research Behind HOPE: What the Experiments Show
Google didn't just theorize about HOPE; they built it, tested it, and published rigorous results:
Language Modeling Performance
On diverse language modeling benchmarks, HOPE achieves lower perplexity than state-of-the-art Transformers and recurrent models at comparable parameter counts. Lower perplexity means better prediction—the model better understands and predicts text patterns.
Long-Context Memory Management
On "Needle-in-a-Haystack" (NIAH) tasks—where relevant information is buried in a long context window and the model must retrieve it—HOPE demonstrates superior performance. The Continuum Memory System successfully identifies and preserves important information while processing extended sequences.
Common-Sense Reasoning
HOPE shows improved performance on reasoning benchmarks that require integrating multiple facts and drawing logical conclusions. This suggests the multi-level memory system is genuinely capturing and utilizing knowledge across different abstraction levels.
Stability and Consistency
Critically, HOPE maintains stable performance as it learns continuously. The multi-speed update mechanism prevents the catastrophic performance drops that typically occur when you retrain models with new data. Adaptation happens gracefully.
HOPE vs. Other Continual Learning Approaches
The AI research community has attempted to solve catastrophic forgetting before. HOPE differs from previous approaches in important ways:
| Approach | Method | Limitations | HOPE Advantage |
|---|---|---|---|
| Replay/Buffer Methods | Store old data, replay it during new training | Memory-expensive, requires storage of past data, doesn't scale | No replay required; learns on different timescales natively |
| Regularization-Based | Constrain parameter updates to preserve old knowledge | Slows learning, requires hyperparameter tuning, brittle | Architectural solution; integrates naturally without constraints |
| Dynamic Expansion | Add new parameters for new tasks | Model grows unbounded, loses knowledge sharing | Fixed architecture; knowledge integrates across scales |
| Nested Learning (HOPE) | Multi-speed parameter updates with self-modification | Still experimental; production timelines uncertain | Principled, scalable, mirrors human learning, proven results |
HOPE is fundamentally different because it's not a patch or workaround. It's an architectural solution that addresses the problem at its root.
The Path to Production: When Will HOPE Be Available?
As of November 2025, HOPE remains experimental. Google has published the research and proved the concept, but commercial deployment timelines haven't been announced. The company is being appropriately cautious about making claims regarding production-ready timelines.
However, several factors suggest commercialization will accelerate:
- Research validation: Publication at NeurIPS 2025 (peer-reviewed top venue) provides academic credibility.
- Proof-of-concept implementation: Google has already built HOPE as a working system, not just a theoretical model.
- Competitive pressure: If HOPE genuinely solves continual learning, OpenAI, Anthropic, and others will move quickly to develop comparable systems.
- Strategic importance: Continual learning is essential for AGI. Google won't sit on this technology.
Conservative estimates suggest prototype deployment within 6-12 months, with broader availability following within 18-24 months. But in the fast-moving AI industry, these timelines compress rapidly once competitive advantage becomes apparent.
Implications for AGI Timeline
Perhaps the most profound question: does HOPE accelerate the timeline to artificial general intelligence?
The conventional wisdom, articulated by Karpathy, placed AGI a decade away primarily due to the continual learning problem. If HOPE genuinely solves this—even 80% of the way—it removes a fundamental barrier that was supposed to take years of research to overcome.
This doesn't mean AGI is imminent. Other challenges remain: reasoning reliability, multi-modal understanding, value alignment, and interpretability. But the removal of catastrophic forgetting as a blocker is significant. It's like discovering a shortcut through a mountain range that was supposed to take years to cross.
Google's own assessment is measured but optimistic: "We believe the Nested Learning paradigm offers a robust foundation for closing the gap between the limited, forgetting nature of current LLMs and the remarkable continual learning abilities of the human brain." This isn't hype. It's a carefully worded statement from a company that's already achieved the breakthrough.
Current Limitations and Open Questions
HOPE is powerful, but it's not a complete solution to all AI challenges:
- Computational efficiency: The multi-level update system adds computational overhead. Production optimization will be crucial.
- Scaling to massive models: HOPE has been tested at modest scales. Scaling to models with hundreds of billions of parameters is an open question.
- Integration with existing tools: Current AI infrastructure (transformers, fine-tuning, prompting) is deeply optimized for standard architectures. Retrofitting HOPE into existing workflows will require engineering effort.
- Theoretical understanding: While HOPE works empirically, the theoretical understanding of why multi-speed learning prevents catastrophic forgetting is still developing.
These aren't fatal limitations. They're engineering challenges that the AI community is well-equipped to solve. The conceptual breakthrough has already happened.
What HOPE Means for Researchers, Developers, and Organizations
For ML Researchers
HOPE opens an entirely new research direction. Understanding how to optimize multi-speed learning systems, how to tune timescale parameters, and how to extend Nested Learning to other domains (vision, multimodal, RL) will occupy researchers for years.
For Developers and Product Teams
Once HOPE reaches production, it will enable new classes of applications. Adaptive AI systems that improve through use. Personalized models that evolve with users. Robots that learn continuously. These applications are being designed now, waiting for HOPE to mature.
For Organizations
Companies building AI-driven products should begin planning for a world where continual learning is standard. Systems designed assuming catastrophic forgetting will need reimagining. Organizations that adapt early will have competitive advantages.
The Broader Context: Why This Moment Matters
November 2025 is emerging as a pivotal month for AI. OpenAI released GPT-5.1 with adaptive reasoning. Google announced HOPE with genuine continual learning. DeepSeek continued advancing reasoning models. These aren't isolated announcements—they're evidence of a field in rapid transition, attacking fundamental problems and making real breakthroughs.
HOPE represents the type of conceptual advance that shifts entire research directions. It's not an incremental improvement to existing approaches. It's a new paradigm: Nested Learning as a fundamental principle for how AI systems should organize knowledge and learning.
Looking Forward: The Next Frontiers
If continual learning is solved by HOPE, what problems remain on the path to AGI?
- Reasoning reliability: Consistent correct reasoning on novel, complex problems.
- Multi-modal understanding: Seamless integration of text, image, audio, video, and other modalities.
- Value alignment: Ensuring AI systems pursue human-compatible goals.
- Interpretability: Understanding why AI systems make decisions.
- Embodied cognition: Learning through physical interaction, not just data.
These are hard problems. But with continual learning solved, the AI community can focus its full attention on these remaining frontiers. The research landscape is shifting. What seemed impossible two years ago—solving catastrophic forgetting—is now proven. What seems impossible today will likely be solved by 2027.
The Bottom Line
Google's HOPE model isn't just another AI release. It's a breakthrough that solves a problem that was supposed to take a decade to overcome. Through Nested Learning, Continuum Memory Systems, and self-modifying architecture, HOPE enables genuine continual learning—something human-like and something AI has never achieved before.
For researchers, it opens new research frontiers. For developers, it promises new application possibilities. For the field of AI, it accelerates the journey toward systems that can learn, adapt, and improve indefinitely—just like human intelligence.
HOPE is experimental today. It will be essential infrastructure tomorrow.
Related Reading
- Deep Learning Category
- Machine Learning Category
- Deep Learning Architectures That Actually Work in 2025: From Transformers to Mamba to JEPA
- AI Reasoning Models Explained: OpenAI O1 vs DeepSeek V3.2 & The Next Leap Beyond Standard LLMs
- AI News & Trends Category
- AI in Drug Discovery 2025: How Machine Learning is Accelerating the Path to Cure in Weeks, Not Years
About the Author
Girish Soni is the founder of TrendFlash and an independent AI strategist covering artificial intelligence policy, industry shifts, and real-world adoption trends. He writes in-depth analysis on how AI is transforming work, education, and digital society. His focus is on helping readers move beyond hype and understand the practical, long-term implications of AI technologies.