Introduction: A Paradigm Shift in Deep Learning
For the past five years, Transformer architectures have dominated deep learning. From GPT models to BERT, from Vision Transformers to multimodal systems, the attention mechanism invented in 2017 became the foundational building block for nearly every major AI breakthrough.
But in 2025, the landscape is shifting. A new generation of architectures is emerging—systems designed to overcome the fundamental limitations that have constrained Transformers since their inception. These aren't incremental improvements. They represent fundamentally different approaches to sequence modeling.
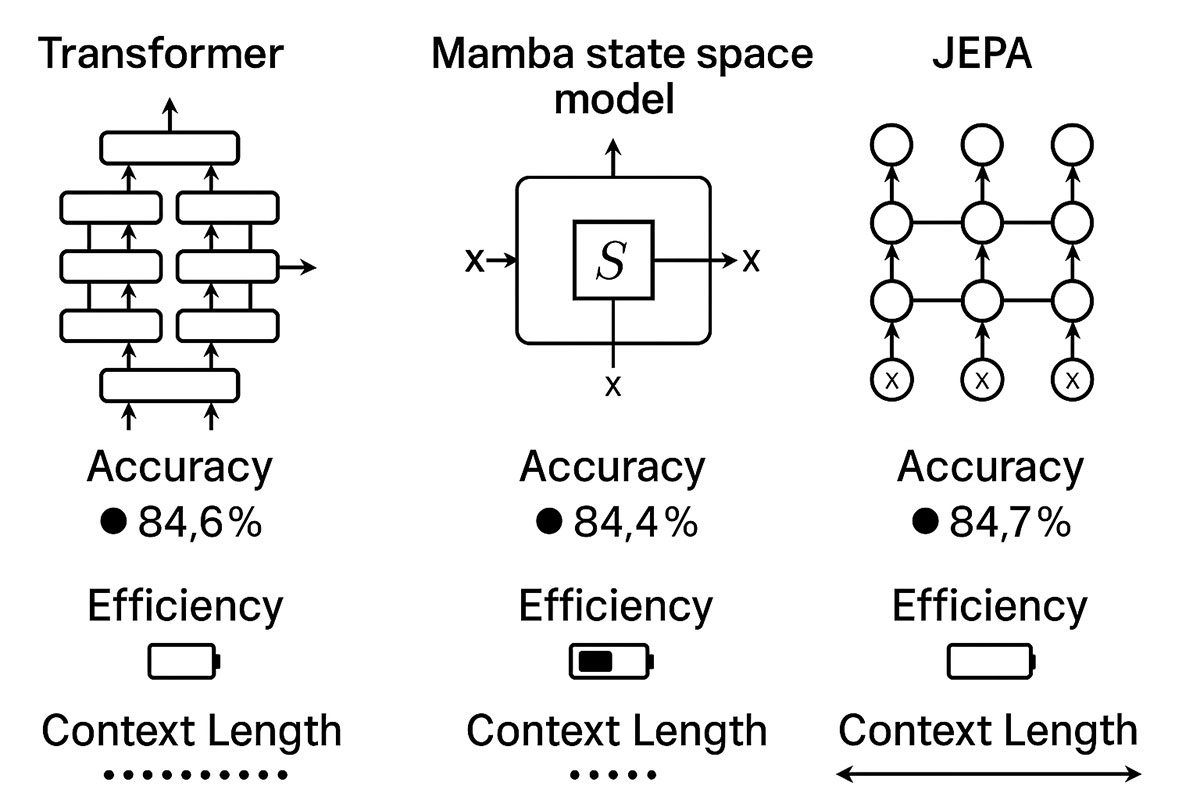
The competition is real. Consider the performance metrics: Mamba models achieving 5× faster inference throughput than comparable Transformers while handling sequences up to 1 million tokens—where Transformers would face prohibitive computational costs. JEPA architectures demonstrating that predicting abstract representations, rather than pixel-level details, leads to more efficient learning and better generalization.
This transformation is happening in real-time. Your choice of architecture directly impacts model performance, training costs, inference speed, memory requirements, and ultimately, business outcomes. Understanding the tradeoffs between competing approaches is no longer academic—it's a critical engineering decision.
The Transformer: Foundation and Limitations
Before exploring alternatives, we must understand why Transformers, despite their power, have fundamental constraints that have driven the search for better approaches.
What Made Transformers Revolutionary
The Transformer architecture, introduced in the 2017 paper "Attention Is All You Need," revolutionized deep learning by introducing the self-attention mechanism. Rather than processing sequences sequentially (as in RNNs) or with limited context (as in CNNs), Transformers can attend to any position in the sequence with equal directness.
Key advantages:
- Parallelizable: All positions in a sequence can be processed simultaneously, enabling efficient training on GPUs
- Long-range dependencies: The attention mechanism directly connects distant positions, capturing long-range patterns that recurrent networks struggle with
- Scalable: Performance improves reliably with increased model size and data
- Transfer learning: Pre-trained Transformers transfer effectively to diverse downstream tasks
These capabilities enabled the explosion of large language models and multimodal AI systems that define modern AI.
The Fundamental Limitation: Quadratic Complexity
Despite their power, Transformers have a critical computational limitation: self-attention requires O(n²) memory and computation, where n is the sequence length.
What does this mean practically?
- Doubling your input sequence length requires 4× more computation
- Processing 100 tokens instead of 10 requires 100× more computational resources
- Processing 1,000,000-token sequences becomes economically prohibitive
This quadratic scaling becomes problematic in scenarios requiring:
- Long context windows (processing entire documents, codebases, or conversations)
- Real-time inference (where computational budget is strictly limited)
- Resource-constrained environments (mobile devices, edge computing)
- Cost-sensitive applications (where GPU hours directly impact profitability)
This limitation has driven the search for alternatives that maintain Transformers' advantages while eliminating the quadratic complexity problem.
Mamba: State Space Models for the Modern Era
Enter Mamba—a revolutionary architecture that achieves linear complexity in sequence length while maintaining competitive or superior performance compared to Transformers.
The Core Innovation: Selective State Space Models
Mamba is built on State Space Models (SSMs), a mathematical framework from control theory that represents systems using differential equations. The innovation is "selectivity"—a mechanism that lets the model adaptively control which information to process based on the current input.
Classical SSMs are time-invariant, meaning they apply the same transformation regardless of input. Mamba introduces input-dependent selectivity, enabling the model to focus on relevant information and ignore irrelevant data—similar to attention, but implemented more efficiently.
How Mamba Works: The Technical Foundation
At each timestep, Mamba processes:
h(t+1) = A(t) * h(t) + B(t) * x(t)
y(t) = C(t) * h(t)
Where:
- h(t) is the hidden state (maintaining context)
- x(t) is the input
- A, B, C are learnable matrices that adapt based on input via selective mechanisms
- The key innovation: these matrices are input-dependent (hence "selective")
This enables the model to process sequences in two modes:
- Recurrent mode: For inference, maintaining constant memory as sequence length grows
- Convolutional mode: For training, enabling parallel computation
Hardware-Aware Implementation
Mamba includes a hardware-aware parallel algorithm leveraging GPU capabilities:
- Kernel fusion: Combines multiple operations into single GPU kernels
- Parallel scan: Enables efficient computation of the recurrent state
- Recomputation: Trades computation for memory efficiency
The result: Mamba achieves 18% lower computational requirements than comparable Transformers at 1B parameters and 8K context length, while being significantly faster in practice.
Performance Benchmarks: Mamba vs Transformers
Empirical results demonstrate Mamba's advantages:
| Metric |
Mamba-3B |
Transformer-3B |
Mamba Advantage |
| Inference Throughput |
5× faster |
Baseline |
5x speedup |
| Max Context Length |
1M tokens |
~100K tokens |
10x longer |
| Memory Requirements |
Linear |
Quadratic |
Scales better |
| Language Modeling (WinoGrande) |
63.5% |
59.7% |
+3.8% accuracy |
| Question Answering (HellaSwag) |
Competitive |
Baseline |
Comparable |
| Training Speed |
Fast |
Baseline |
30% reduction in training time |
Notably, Mamba-3B matches the performance of Transformers approximately twice its size, demonstrating that efficiency gains don't require accuracy sacrifices.
Specialized Task Performance
Mamba demonstrates exceptional performance on long-sequence tasks:
- DNA Classification: On Great Apes DNA sequences (1 million tokens), Mamba achieved 70% accuracy vs Hyena DNA's 55% accuracy using models of 1.4B parameters
- Genomics: Mamba processes genomic sequences far longer than Transformers can handle efficiently
- Time-series: Outperforms Transformers on tasks with long-range temporal dependencies
Practical Advantages for Deployments
In production environments:
- Inference Latency: 5× speedup compared to Transformers
- Batching Efficiency: Recurrent mode enables constant-size batches regardless of sequence length
- Memory Footprint: Single GPU can handle longer sequences than with Transformer competitors
- Scalability: Linear complexity enables scaling to longer contexts without exponential cost increases
Vision Transformers (ViT) and CNNs: The Computer Vision Showdown
While Mamba addresses sequence modeling efficiency, a parallel revolution is reshaping computer vision: the competition between Vision Transformers and traditional Convolutional Neural Networks.
Convolutional Neural Networks: Principles and Strengths
CNNs have dominated computer vision since AlexNet's breakthrough in 2012. Their principles:
- Inductive Bias: Convolutional kernels encode the assumption that features should be detected at all spatial locations
- Spatial Hierarchy: Features learned at early layers (edges) are combined into higher-level features (objects)
- Computational Efficiency: Convolutions are highly optimized on hardware; moderate memory requirements
- Parameter Sharing: Same kernel weights apply across entire image, reducing parameter count
CNN Performance in 2025:
| Architecture |
Parameters |
ImageNet Accuracy |
Inference Speed |
Memory |
| ResNet-50 |
25.5M |
79.95% |
Fast |
Moderate |
| EfficientNet-B0 |
4.0M |
88.05% |
Very Fast |
Low |
| MobileNet |
~3-5M |
85-90% |
Extremely Fast |
Very Low |
CNNs excel in scenarios with:
- Limited computational budgets
- Smaller training datasets
- Edge deployment requirements
- Texture-heavy tasks (skin lesion classification, fine-grained recognition)
Vision Transformers: Attention-Based Vision
Vision Transformers divide images into patches, embed them as sequences, and apply standard Transformer attention. Key characteristics:
- Global Context: Attention directly connects every patch to every other patch from the first layer
- Scalability: Performance improves reliably with increased model size and data
- Transfer Learning: Pre-trained ViTs transfer effectively to downstream tasks
- Flexibility: Same architecture handles diverse vision tasks
ViT Performance Benchmarks:
| Architecture |
Parameters |
ImageNet Accuracy |
Data Efficiency |
Global Context |
| ViT-Base |
85.8M |
85.64% |
Moderate |
Excellent |
| DeiT-Small |
21.7M |
90.38% |
Good |
Excellent |
| Swin Transformer |
Variable |
92%+ |
Strong |
Strong |
ViTs demonstrate 4.01% higher average accuracy compared to CNNs across diverse medical imaging tasks, with significantly lower variance in performance—indicating more consistent results across different scenarios.
Head-to-Head Comparison: When Each Wins
The choice between CNNs and ViTs depends on specific requirements:
Vision Transformers Win When:
- Large datasets are available (ImageNet-scale or larger)
- Global context relationships matter (scene understanding, large-scale object detection)
- Transfer learning to diverse downstream tasks is required
- Computational resources are abundant
- You need state-of-the-art accuracy
Real-world advantage: ViTs showed superior robustness at distance in face recognition. CNNs achieved random performance at 30 meters; ViTs maintained 63% accuracy, indicating superior long-range visual understanding.
CNNs Win When:
- Dataset size is limited (< 10K images)
- Real-time inference is required
- Memory constraints exist (mobile, edge devices)
- Texture-based recognition is important
- Cost per inference is critical
Real-world advantage: On chest X-ray analysis, CNNs achieved 98.37% accuracy vs ViT's 92.82%—CNNs better handle the subtle, localized patterns in radiographs.
The Hybrid Approach: Best of Both Worlds
Recent research shows that mixing Transformer and Mamba blocks often outperforms homogeneous architectures. Similarly, hybrid architectures combining CNN and Transformer blocks achieve:
- Better accuracy than pure CNNs
- Better efficiency than pure Transformers
- Flexibility for diverse tasks
This suggests the future isn't "one architecture wins all"—it's intelligent selection of which components to use where.
JEPA: Learning World Models for General Intelligence
While Mamba optimizes efficiency and ViTs optimize accuracy, JEPA tackles a more fundamental question: How should AI systems learn about the world?
The Vision: Yann LeCun's World Models
JEPA (Joint Embedding Predictive Architecture) is based on Yann LeCun's vision for achieving machine common sense. Rather than training models to predict every pixel or token detail, JEPA trains systems to predict abstract representations of the world.
The principle: Humans don't learn by predicting pixel details. We learn by passively observing the world and building an internal model of how it works. This "world model" enables:
- Sample efficiency: Learning with far less labeled data
- Rapid adaptation: Quickly adjusting to new situations
- Planning: Understanding potential future states before acting
- Common sense: Intuitive understanding of physical and social dynamics
How JEPA Works: Abstract Representation Prediction
JEPA's architecture has three main components:
- Encoder: Processes inputs (images, video frames, text) into abstract representations
- Predictor: Predicts representations of unobserved parts based on observed parts
- Target Encoder: Generates target representations (processed through student-teacher framework for stability)
Rather than predicting missing pixels, JEPA predicts the abstract representation of the masked region. This removes unnecessary details while preserving semantic information.
I-JEPA: Image Understanding Without Pixel Prediction
The first implementation, I-JEPA (Image JEPA), demonstrates this principle:
- Trained on unlabeled images by predicting abstract representations of masked image blocks
- Achieves state-of-the-art low-shot classification using only 12 labeled examples per ImageNet class
- Requires 16 A100 GPUs under 72 hours—dramatically more efficient than traditional pre-training
- Learns semantic features without hand-crafted data augmentations
- Better at low-level vision tasks (object counting, depth prediction) than pixel/token reconstruction methods
V-JEPA: Video Understanding and Dynamic Prediction
Building on I-JEPA, V-JEPA (Video JEPA) extends the approach to temporal understanding:
- Predicts abstract representations of future video frames
- Detects and understands complex object interactions
- Learns spatial and temporal relationships simultaneously
- Moves toward Yann LeCun's vision of "advanced machine intelligence"
Why JEPA Matters: Implications for AI Architecture
JEPA represents a philosophical shift:
- Efficiency: Learning meaningful representations requires less data and computation
- Robustness: Abstract representations are more robust to noise and variations
- Generalization: World models transfer better to novel tasks than task-specific training
- Scaling: JEPA's efficiency enables scaling to larger models and datasets
Early results suggest JEPA approaches could be crucial for achieving AI systems that learn and adapt like humans.
Practical Comparison: Choosing Architecture for Your Application
The decision between Transformers, Mamba, ViTs, CNNs, and JEPA depends on specific application requirements:
Language Models and NLP
| Use Case |
Best Architecture |
Rationale |
| Long-context processing (100K+ tokens) |
Mamba |
Linear complexity enables long sequences |
| Production LLMs (cost-sensitive) |
Mamba |
5× inference speedup reduces costs |
| Research and benchmarks |
Transformer |
Established ecosystem and comparability |
| Emerging modalities |
Hybrid architectures |
Combines Transformer and Mamba strengths |
| Reasoning-heavy tasks |
Transformer |
Superior reasoning capabilities (current generation) |
Computer Vision
| Use Case |
Best Architecture |
Rationale |
| Small dataset (< 10K images) |
CNN |
Better efficiency with limited data |
| Large-scale classification |
Vision Transformer |
Superior accuracy with abundant data |
| Real-time inference (edge) |
Lightweight CNN |
Speed and memory constraints |
| Fine-grained recognition |
Vision Transformer |
Superior at detailed visual relationships |
| Hybrid tasks |
Swin Transformer |
Efficient hierarchical attention |
Efficiency-Critical Applications
| Use Case |
Best Architecture |
Rationale |
| Mobile deployment |
MobileNet/Efficient architectures |
Minimal parameters and memory |
| Real-time processing |
CNN or lightweight Transformer |
Latency requirements |
| Cost minimization |
Mamba for sequences, CNN for vision |
Reduced computational overhead |
| Long-sequence processing |
Mamba |
Only architecture practical for million-token sequences |
Research and Exploration
| Use Case |
Best Architecture |
Rationale |
| World model development |
JEPA variants |
Foundational research direction |
| Multimodal systems |
Hybrid Transformers |
Flexibility across modalities |
| Novel domains |
Transformer (proven) or Mamba (efficient) |
Established and reliable |
Implementation Examples: Real Code and Benchmarks
Using Mamba for Long-Sequence Tasks
import torch
from mamba_ssm.models.mixer_seq_simple import MambaLMHeadModel
# Load pre-trained Mamba model
model = MambaLMHeadModel.from_pretrained("state-spaces/mamba-1.4b-hf")
# Process extremely long sequences efficiently
input_ids = torch.randint(0, 50256, (1, 1_000_000)) # 1M token sequence
# Mamba handles this with linear memory
with torch.no_grad():
output = model(input_ids) # Practical, not theoretical
This same code with a Transformer would hit memory limits or require expensive optimizations.
Using Vision Transformers for Image Classification
import torch
from transformers import AutoImageProcessor, AutoModelForImageClassification
# Load ViT model
processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224-in21k")
model = AutoModelForImageClassification.from_pretrained("google/vit-base-patch16-224")
# Process images
image_data = processor(image, return_tensors="pt")
with torch.no_grad():
outputs = model(**image_data)
logits = outputs.logits
predictions = torch.argmax(logits, dim=-1)
ViTs typically outperform CNNs on ImageNet-scale datasets.
CNN for Efficient Mobile Deployment
import torch
from torchvision import models
# EfficientNet-B0: 4M parameters, ~88% accuracy
model = models.efficientnet_b0(pretrained=True)
# Mobile-friendly: ~14MB model size, ~15ms inference on iPhone
model.eval()
# Quantization for further efficiency
quantized_model = torch.quantization.quantize_dynamic(model)
with torch.no_grad():
outputs = quantized_model(image)
Perfect for edge deployment where memory and latency are constrained.
Benchmarking Methodologies and Performance Metrics
When evaluating architectures, comprehensive benchmarking matters:
Key Metrics to Evaluate
- Accuracy: Task-specific performance (ImageNet top-1 for vision, perplexity for language)
- Inference Latency: Time per forward pass (milliseconds)
- Throughput: Samples processed per second
- Memory Usage: Peak memory during training/inference
- Parameter Count: Number of learnable weights
- Training Time: Hours/days to reach target accuracy
- Energy Efficiency: FLOPS per watt
Industry Benchmarks
- MLPerf: Industry-standard benchmarks for ML performance
- ImageNet: Vision benchmarks across diverse CNN and ViT architectures
- GLUE/SuperGLUE: Language understanding benchmarks
- Long Range Arena: Specifically tests long-sequence modeling
Recent results show:
- Mamba outperforms Transformers on long-sequence benchmarks
- Vision Transformers beat CNNs on ImageNet when data is abundant
- Hybrid architectures achieve best-of-both-worlds performance
When to Migrate Between Architectures
Consider migrating from established architectures when:
- Computational constraints emerge: Switch to Mamba if inference costs become prohibitive
- Sequence length requirements increase: Mamba enables 10× longer sequences
- Accuracy plateaus: Try ViTs if CNN accuracy hits ceiling
- Data scale changes: Transition to ViTs as data increases
- New capabilities needed: JEPA for world modeling and reasoning
But maintain current architectures when:
- System is working well and meets requirements
- Team expertise aligns with current stack
- Ecosystem maturity matters (Transformers have largest ecosystem)
- Production stability is paramount
The Future: Convergence and Specialization
Where are deep learning architectures heading?
Likely Developments:
- Task-specific specialization: Different architectures dominating different domains
- Hybrid approaches: Models combining Transformer, Mamba, and CNN components
- Efficiency-first design: Linear complexity becoming the default
- World models: JEPA-like approaches enabling more general intelligence
- Heterogeneous computing: Different model components optimized for different hardware
- Continuous learning: Architectures supporting ongoing adaptation without retraining
The clear trajectory: we're moving from one-architecture-fits-all toward intelligent selection of components based on task requirements.
Conclusion: Making the Right Architecture Choice
In 2025, choosing a deep learning architecture requires understanding tradeoffs rather than picking a winner:
- Transformers: Proven, flexible, best ecosystem, but computationally expensive at scale
- Mamba: Revolutionary efficiency, linear complexity, but newer with smaller ecosystem
- Vision Transformers: Superior accuracy on large-scale vision tasks, but data-hungry
- CNNs: Unmatched efficiency on small datasets and edge devices
- JEPA: Foundational for world models, but still emerging
The organizations winning in 2025 won't use one architecture—they'll strategically deploy the right architecture for each problem, using proven benchmarks to make data-driven decisions.
Start by understanding your specific constraints: latency requirements, memory budgets, dataset size, sequence length needs. Then match those constraints to the architecture that provides the best solution.
The era of architecture monoculture is ending. The era of intelligent architecture selection has begun.
Related Resources:
For deeper technical knowledge on AI architectures and implementation, explore these resources: