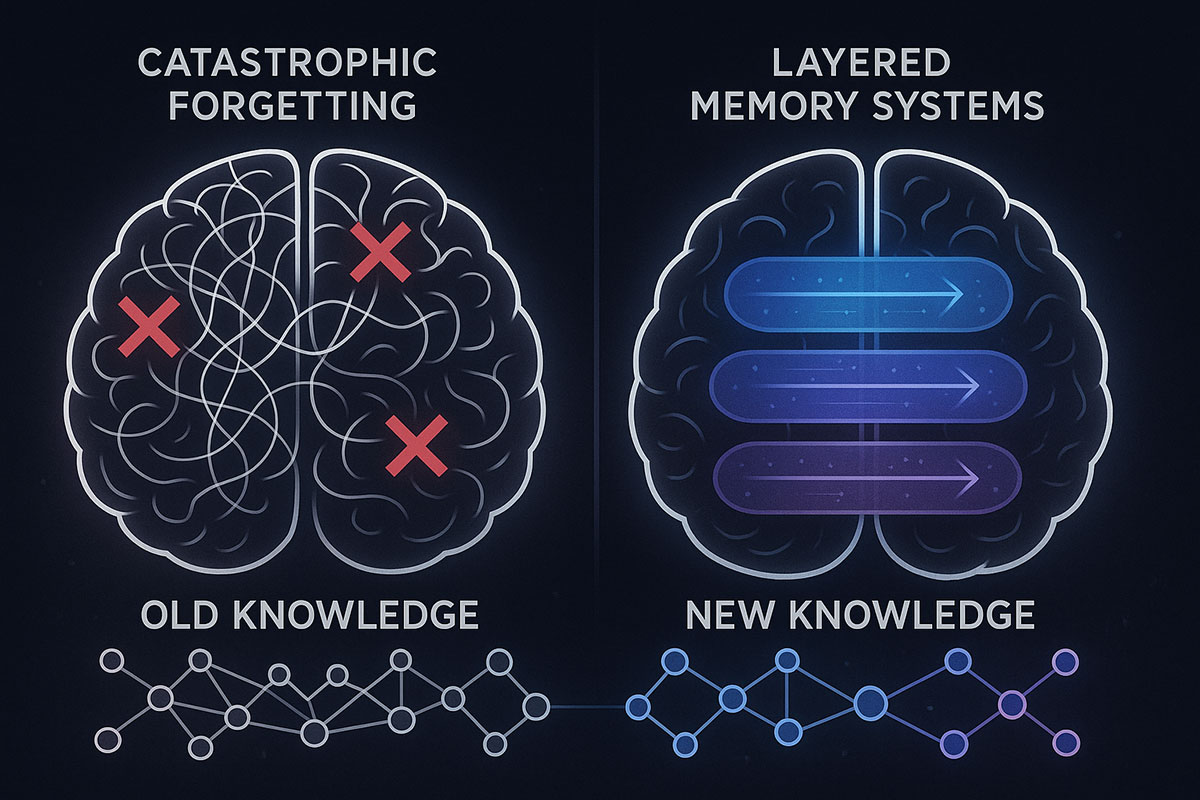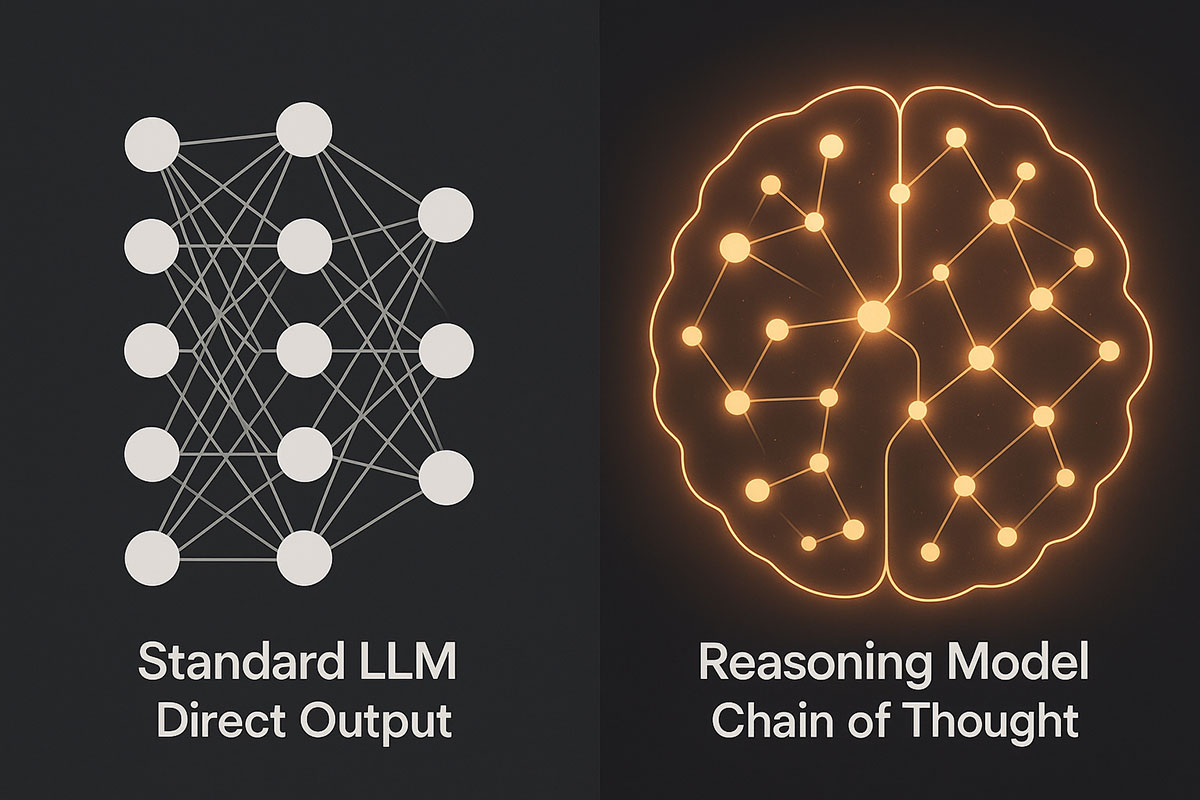
Introduction: Why Algorithm Knowledge Still Matters in 2025
In an era of pre-trained models and AutoML platforms, do developers still need to understand individual machine learning algorithms? The answer is unequivocally yes. While high-level frameworks abstract away implementation details, understanding how algorithms work enables you to debug failures, optimize performance, choose appropriate techniques for specific problems, and innovate beyond what existing tools provide.
This comprehensive guide covers 10 essential algorithms that remain foundational in 2025, even as the AI landscape evolves toward larger models and more automated approaches. Whether you're building machine learning systems, developing AI productivity tools, or pursuing an AI career, this knowledge forms an essential foundation.
1. Linear Regression: The Foundation of Predictive Analytics
Core Concept
Linear regression is the simplest supervised learning algorithm, modeling the relationship between input features and a continuous output variable using a straight line (or hyperplane in multiple dimensions).
Mathematical Foundation
The algorithm finds optimal coefficients (weights) by minimizing the difference between predicted and actual values. Despite its simplicity, linear regression teaches fundamental ML concepts: loss functions, gradient descent optimization, and regularization techniques.
Best Use Cases
- Housing price prediction from features like square footage and location
- Sales forecasting based on historical trends
- Demand estimation for inventory planning
- Risk scoring in financial applications
Strengths & Limitations
Strengths: Interpretable, computationally efficient, fast to train, works well when relationships are approximately linear.
Limitations: Assumes linear relationships; highly sensitive to outliers; poor performance when data violates linearity assumptions.
Evaluation Metrics
- RMSE (Root Mean Squared Error): Penalizes large errors heavily
- MAE (Mean Absolute Error): Average magnitude of errors
- R² Score: Proportion of variance explained (0-1 scale)
- Residual Plots: Visual inspection of error patterns
In practice, always examine residual plots to ensure linear regression's assumptions hold before deploying models in production.
Conclusion: Mastering Foundational Algorithms
Master these algorithms, and you'll understand the reasoning behind virtually any machine learning system. You'll know when to apply which technique, how to debug failures, and how to innovate beyond existing approaches.
The future belongs to those who understand these fundamentals deeply enough to build on them creatively. Start here, go deeper, and contribute to the next evolution of intelligent systems.
Continue your learning journey with our comprehensive guides on the latest ML algorithms, recent breakthroughs, and emerging AI trends.
About the Author
Girish Soni is the founder of TrendFlash and an independent AI strategist covering artificial intelligence policy, industry shifts, and real-world adoption trends. He writes in-depth analysis on how AI is transforming work, education, and digital society. His focus is on helping readers move beyond hype and understand the practical, long-term implications of AI technologies.