Introduction: The Reasoning Revolution in AI
For years, we've relied on large language models to generate text rapidly—processing queries in milliseconds and returning answers almost instantaneously. But there's a fundamental limitation to this approach: sometimes problems require genuine thinking. In 2025, this assumption is being challenged by a new generation of AI reasoning models that deliberately spend computational time solving complex problems systematically.
OpenAI's o1 and DeepSeek's V3.2 represent the cutting edge of this transformation. Rather than pattern-matching against training data, these models actually reason through multi-step problems—much like a human mathematician working through a proof or a programmer debugging intricate code. This shift from reflexive response to deliberate reasoning opens possibilities that traditional LLMs simply cannot match.
Understanding the Fundamental Difference: Reasoning vs. Standard LLMs
The distinction between standard language models and reasoning models isn't just a matter of degrees—it's a categorical difference in how these systems operate.
Standard LLMs (GPT-4o, Claude 3.5 Sonnet, Llama 3.3)
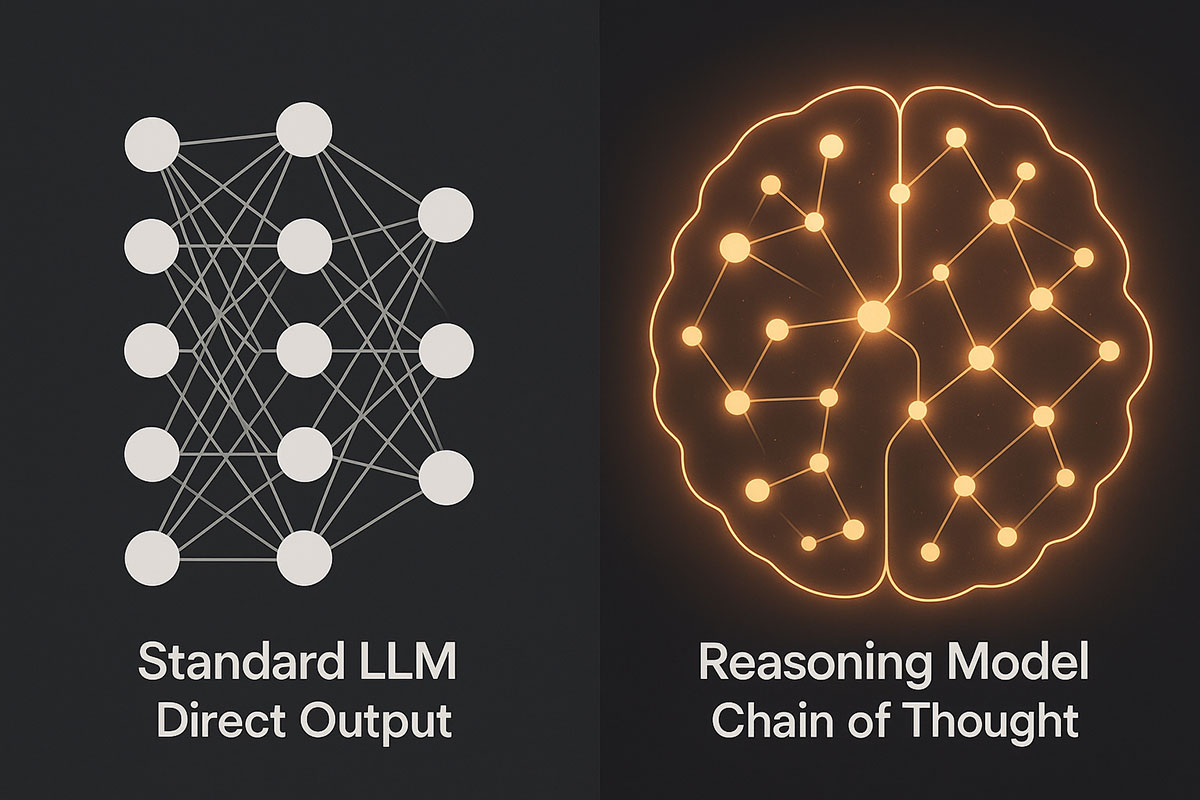
Standard LLMs operate through immediate inference. When you ask a question, they pattern-match against their training data and generate a response directly. This approach excels at tasks that require broad knowledge synthesis, creative writing, and rapid response times. However, they often fail at problems requiring deep logical chains or multi-step verification.
Reasoning Models (O1, DeepSeek-V3.2, Gemini 2.5 Pro Reasoning)
Reasoning models employ a fundamentally different architecture. They generate extended "chains of thought"—internal reasoning traces where the model works through problems step-by-step before producing a final answer. Think of it like seeing both a mathematician's scratch work and their final solution, rather than just the answer alone.
OpenAI describes this as "inference-time scaling"—instead of making the model larger or training it longer, they're allocating more computational resources at inference time to thinking rather than generation. The model literally pauses to reason before responding.
How These Models Actually Think: The Technical Foundation
Understanding the mechanics of reasoning reveals why these models perform so differently.
OpenAI O1's Process Reward Model (PRM) Architecture
O1 employs a sophisticated mechanism called a Process Reward Model that functions as both generator and verifier. Rather than committing to the first plausible answer (the traditional "pass@1" approach), O1 continuously assesses and refines its own outputs through an internal verification loop. This self-correction capability isn't explicitly programmed—it emerged naturally from increasing inference-time compute.
The "Berry Training" system that powers O1 generates hundreds of trillions of tokens across diverse reasoning paths for each problem. These aren't random explorations; they're carefully curated trajectories where multiple solutions may share common starting points before diverging. OpenAI then uses functional verifiers and Optimal Reward Models (ORM) to filter weak answers, retaining only those that meet accuracy thresholds.
This approach flips traditional AI development on its head. While most models invest heavily in pre-training compute, O1's post-training phase actually demands more compute than initial training—multiple verification models run in parallel to ensure correctness before deployment.
DeepSeek-V3.2's Sparse Attention Innovation
DeepSeek approaches reasoning through a different lens: aggressive efficiency. V3.2 employs Multi-head Latent Attention (MLA) and advanced Mixture of Experts (MoE) architectures to achieve reasoning capabilities without proportional cost increases.
The breakthrough innovation is sparse attention—instead of computing attention across all tokens, the model selectively focuses on the most relevant parts of its input, similar to how humans scan documents for important information. This architectural choice doesn't sacrifice reasoning quality; instead, it preserves accuracy while dramatically reducing computational overhead.
DeepSeek's reasoning model can generate up to 64K tokens of reasoning content (defaulting to 32K) before producing its final answer. Remarkably, DeepSeek-V3.2-Exp achieves reasoning performance comparable to its flagship R1 model while responding faster and reducing chain-of-thought tokens by 20-50%.
Performance Comparison: Where These Models Excel
Real-world benchmarks reveal the practical differences between these systems.
| Benchmark Category |
OpenAI O1 |
DeepSeek-V3.2 |
Standard LLM (GPT-4o) |
Use Case |
| Mathematical Reasoning |
85-92% accuracy on MMLU |
84-88% accuracy on MMLU |
78-85% accuracy |
Complex proofs, calculus, algebra |
| Software Engineering |
Superior on SWE-bench |
Excellent code debugging |
Moderate performance |
Multi-step debugging, architecture design |
| Scientific Problem-Solving |
Exceptional on GPQA |
Strong performance |
Moderate results |
Physics problems, chemistry reactions |
| Response Latency |
15-30+ seconds |
8-15 seconds |
<2 seconds |
Production use-case consideration |
| Cost Per Query |
Higher ($0.015-0.030) |
Lower ($0.008-0.015) |
Baseline |
Long-context operations |
The data reveals a strategic tradeoff: reasoning models sacrifice speed and cost efficiency for correctness on genuinely complex problems. For tasks where accuracy matters more than latency—scientific research, critical code review, legal analysis—the investment makes sense.
Why Sparse Attention Matters: The Cost Reduction Story
One of the most significant developments in late 2025 is DeepSeek's validation that sparse attention can reduce API costs by up to 50% for long-context operations without proportional quality loss.
This matters because inference costs represent the largest operational expense for deploying reasoning models at scale. A long research document or codebase requiring reasoning might cost dollars to process on dense attention models. By selectively attending to relevant sections, sparse models achieve similar quality at substantially lower cost.
The mechanism: sparse attention reduces peak GPU memory requirements and cuts FLOPs (floating-point operations) during both training and inference. For teams processing long documents repeatedly—legal discovery, research paper analysis, comprehensive code review—this represents genuine economic advantage.
Real-World Applications Reshaping Industries
The practical applications of reasoning models are already emerging across sectors.
Scientific Research and Discovery
Reasoning models accelerate hypothesis generation and validation. Researchers working on novel drug compounds can use O1 or DeepSeek-V3.2 to analyze protein structures, predict molecular interactions, and identify promising candidates. The model's ability to work through complex biochemical reasoning makes it competitive with domain experts for specific tasks.
Software Engineering and Debugging
Engineers report that reasoning models excel at multi-step debugging workflows. A complex bug requiring understanding interactions across multiple functions, database queries, and API integrations—exactly where standard LLMs struggle—becomes tractable for reasoning models. The chain-of-thought capability means developers see the model's logic, not just the fix.
Legal and Financial Analysis
Contract analysis, regulatory compliance assessment, and investment thesis evaluation all benefit from reasoning models' structured thought processes. These high-stakes domains particularly value transparency—seeing how the model arrived at conclusions matters as much as the conclusion itself.
Mathematics and Physics Problem-Solving
From competition mathematics to graduate-level physics, reasoning models demonstrate capabilities approaching domain experts. This has immediate applications in education (personalized tutoring for genuine problem-solving) and research (accelerating exploration of theoretical spaces).
Benchmark Deep-Dive: MMMU, GPQA, and SWE-Bench
Beyond general benchmarks, specialized tests reveal where reasoning models genuinely differentiate.
MMMU (Massive Multitask Multimodal Understanding)
Combines text and images to test reasoning across multiple modalities. Reasoning models outperform standard LLMs by 5-15 percentage points, suggesting genuine advantage for multimodal reasoning tasks like medical imaging interpretation or technical diagram analysis.
GPQA (Graduate-level Google-Proof Q&A)
PhD-level questions requiring deep reasoning. Here, reasoning models show their most impressive gains—often achieving 20+ point improvements over non-reasoning models on these exceptionally difficult problems.
SWE-Bench (Software Engineering Benchmark)
Real-world GitHub issues requiring code understanding and fixes. Performance on SWE-bench improved 67.3 percentage points in a single year, suggesting exponential progress in code reasoning capabilities.
Integration Guide: Building Reasoning Models into Production
For development teams considering these models, practical integration requires thoughtful strategy beyond simple API calls.
1. Identify High-Value Reasoning Workloads
Not every task benefits from reasoning models. Prioritize:
- Complex multi-step logic problems
- Situations where error cost is high
- Tasks requiring transparency and explainability
- Problems where current solutions frequently fail
Start by auditing your production systems for failures that reason-through-before-responding could address.
2. Implement Tiered Autonomy
Design your system with three levels:
- Assistive: The reasoning model suggests reasoning paths for human review
- Collaborative: The model handles certain reasoning steps while humans supervise
- Autonomous: The model manages complete reasoning workflows with humans reviewing final outputs
Begin in assistive mode to build organizational trust and confidence.
3. Handle Extended Latency
Reasoning models require 15-30+ seconds per query. Architect your systems to:
- Queue reasoning requests asynchronously
- Provide user feedback during processing
- Cache reasoning results for similar queries
- Implement fallback to faster models for time-sensitive queries
4. Establish Clear Governance Boundaries
Define categories where reasoning model autonomy is permitted and where human oversight is mandatory. For financial decisions, medical recommendations, or legal analysis, maintain human review even as automation increases.
Cost Analysis: When Reasoning Models Make Economic Sense
Reasoning models cost 2-5x more per query than standard LLMs. This premium requires clear justification.
Cost-Benefit Framework:
- High-error-cost domains (medicine, finance, law): Justify premium through error reduction
- Knowledge work acceleration: A lawyer using O1 to analyze contracts 4x faster justifies the cost through productivity gains
- Research and development: Accelerating discovery cycles justifies extended reasoning time and cost
- Low-stakes automation: Customer service, content generation—standard LLMs remain appropriate
For long-context operations, DeepSeek's sparse attention model provides meaningful cost reduction, making reasoning viable for larger-scale applications.
The Limitations and Honest Assessment
Reasoning models aren't panaceas. Current limitations include:
Hallucination Persistence
Even with reasoning traces, models can "reason" themselves toward incorrect conclusions. The transparency helps humans identify errors, but reasoning doesn't eliminate hallucinations.
Simple Tasks Show No Improvement
Asking O1 "What is the capital of France?" provides no benefit over GPT-4o—and costs significantly more. Reasoning time benefits complex problems, not factual recall.
Task-Dependent Effectiveness
Long-range reasoning shows marginal improvement over dense attention models. DeepSeek's sparse attention remains less effective for tasks requiring global context.
Consistency Trade-offs
While reasoning models generally improve accuracy, they sometimes overthink simple problems or become inconsistent on edge cases.
The Future: Toward Collaborative Human-AI Reasoning
The trajectory suggests not replacement of human reasoning, but partnership with specialized AI agents taking on specific reasoning responsibilities. Humans will increasingly provide direction and oversight while AI handles structured reasoning tasks.
Future developments likely include:
- Retrieval-augmented reasoning: Models will reason directly over knowledge bases rather than relying on training data
- Multi-agent collaboration: Complex problems will be broken across multiple specialized reasoning models
- Inverse scaling laws: Problems where larger models historically underperform may benefit from reasoning approaches
- Domain-specific reasoning models: Purpose-built systems for medicine, law, software engineering
Related Reading
For deeper exploration of AI capabilities and strategy: